

IN WHICH WE WILL LEARN:
- The WRONG way to write a prompt:
- Misuse “photorealistic, 8k, and Surrealism“
- Use ten different words to say “take a nice photo”
- Repeat your prompt twelve (12) times, each one wrong in different ways
- Like seriously, DO NOT do this
- Use more tokens than Stable Diffusion allows by an order of magnitude
- Get almost done with your monster prompt, freak the frack out, enter a fugue state, and write “woman with a white face face face face… face 99 times“
- I cannot stress enough how very, very wrong this prompt is.
- But I can fix it.
NOTE: This article is an off-shoot of “What 8k Does to Your Prompt” You may want to read that post first. It has Redhead Space Marines.

What 8k Does to Your Prompt
When I started this blog
so many months 24 days ago, I made a decision to write about what makes bad prompts in general, and not pick on any specific prompts. To make fun of my own experiences to prove a point, but never to belittle other prompters. To be blunt, but never cruel.
But today I saw a prompt the likes of which I have never seen. A prompt so misguided, so confusing, so completely and totally wrong that I could not stay silent. So for the first, and hopefully last time in the long, long history 24 days’ existence of Topless Velociraptor, I present:
The Wrongest Prompt Ever.
So wrong, I can’t even use correct grammar to describe it.
To obfuscate the identity of the prompter from everyone except those willing to do a simple internet search, I will omit the image that resulted from this prompt. It is a pretty nice picture, but not nearly nice enough to justify this monstrosity.
If you didn’t master barely pass Mandarin in high school, you may not be able to see the subtle you still can’t miss at least one or three of the glaring problems this prompt has.
Let’s start with the fugue state weirdness near the end: the 99 面s.
面 means ‘face.’ They say ‘face’ 99 times in a row, broken only once by ‘woman, white face’ (different ‘face’ – 脸 instead of 面.) Or it could be 脸面, which also means ‘face,’ and they could mean 面面, which means ‘multiple viewpoints.” In which case they are asking for 49 viewpoints of a white woman’s face. Shit’s baffling. I am fully baffled. Baffled and a half.

Continuing the crazy repetition of this prompt, they use ‘8k’ eleven times, and ‘RAW’ eleven times as well. ‘Portrait,’ ‘photograph,’ and ‘photorealistic,’ twelve times. (I will come back to this misguided juxtaposition in a moment.) In fact, this mega-prompt is almost, but not quite the same prompt 12 times. Like, bruh (and yeah, it’s definitely a bruh) could have just copied and pasted it, but instead, he chose to type it out, changing a couple of words (or 99) every time.
Why??? I know that I have said that repetition can be a prompter’s best friend, but this is not friendship. My dude shacked up with repetition and has been living in a house with it for years. And years. And years.

It’s not just the 99 ‘face’s
or the eleven-too-many prompts. In addition, more than half of the words within the smaller little mini-prompts, over 50% of them, are also redundant, too. ‘Portrait,’ ‘photography,’ ‘lifelike,’ ‘photorealistic,’ ‘8k,’ ‘highly detailed,’ ‘high-detail RAW color art,’ ‘shallow depth of field,’ ‘sharp focus,’ and arguably ‘detailed skin,‘ (a bit creepy, that one) all essentially mean “a good photo.” (except for 8k, which I address in a different article, and one other word which, again, I will get to) ‘Visible to the whole body’ and ‘full-length frame’ mean the same thing as well. On the other end of the repetition spectrum, ‘Diffuse soft lighting’ and ‘movie lighting’ are almost polar opposites – the first calls for a wash of light evenly illuminating everything, and the second calls for moody lighting with dramatic highlights and shadows (at least as far as Stable Diffusion is concerned – filmmakers might argue this point). Here – look at:
vs
Sexy Cthulu in diffuse soft lighting

Sexy Cthulu in movie lighting

I always say, get yourself a woman who’s Yog-sothoth in the streets and Cthulu in the sheets. Which of these do you think would send you careening over the edge to madness faster?
‘Holding a fairy wand,’
‘looking at the audience,’ and ‘surrealism’ (Surrealism? You spent almost 40 tokens trying to get the most realistic photo ever, and now you want it to be Surrealistic?) are the only unique prompts, and ‘Surrealism’ is too much cognitive dissonance even for me. Oh, and there’s also ‘perforation’ and ‘edas waves,’ which I’m completely stumped by.
All in all, my brother prompter uses the equivalent of four hundred seventy-eight English words (some of which are actual English words) to ask for a “high-quality full-body photo of a white woman holding a fairy wand.”
But the kicker,
the one detail that pushes this prompt into the Annals of Absolutely Audacious Absurdity, is this: ((全身可见)), which translates to ‘full body – this detail is 1.21 times as important as all the other details’ Now what, pray tell, is the only AI model that uses parentheses like this? I’ll give you a hint: it rhymes with “Babel Confusion,” Nimrod’s bane and supposedly the reason we have Mandarin and English to begin with.
And what, pray tell, is one of the biggest limitations of Stable Diffusion? The maximum 77-token prompt length, perhaps? If you don’t know what that is, like my man Face Face obviously doesn’t, I don’t have time to explain, just go read this after you’re done here, it’ll explain the whole thing in more detail than you could possibly want.

Suffice it to say, this absolute mad lad
used more tokens just saying “face” in one section of his prompt than Stable Diffusion can handle in a whole prompt. (He says “face” an uncounted amount of times before and after this, as well. “Uncounted”, as in “I refuse to count them.”)
There is no way I’m going to actually try to tokenize this monstrosity, but a fair estimate would be that this prompt uses somewhere between 600 and 700 tokens. Let’s just round up to “an order of magnitude bigger than Stable diffusion can handle” and call it a day.
So in what I can only imagine was a frustrated attempt to get Stable Diffusion to just make a damn picture of a woman holding a friggin fairy wand already, Mr. Face Face has guaranteed that it will do nothing other than shit itself and flee in terror from this monster prompt.
I suppose it could have been worse. He could have asked for it to be “in the style of Greg Rutkowski” twelve times.

Here’s how I would fix this prompt:
First, burn it down and start fresh with better ways to say what he wants, thusly:
仙女林
獲獎照片佳能EOS 5D
動態構圖動態姿勢
戲劇性的燈光 硬邊燈 上照燈
美麗而銳利的歐洲眼睛
美麗蒼白的臉
金發小精靈剪裁
銀色拖鞋 銀色裙子 銀色上衣
拿著一根閃閃發光的魔杖的歐洲仙女
走向相機
I assume that Stable Diffusion would count each word as a token, not each character. Otherwise, I’m six tokens over budget. Better than 600+ over, I guess.
‘Award-winning photograph’ up there at the top will get us a better picture than a million ‘photorealistic’s, and mentioning the camera… What’s that? Oh. You want it in English. Well, okay, but the subtle lyricism really only works in a tonal language. You miss a lot of poetic wordplay if you don’t read it in the native Mandarin.
Fairy grove
Award-winning photograph Canon EOS 5D
dynamic composition dynamic poses
dramatic lighting hard rim light uplight
Beautiful piercing European eyes
Beautiful pale face
Blonde pixie cut
Silver slippers silver skirt silver blouse
European fairy holding a sparkly magic wand
walking toward the camera
45 tokens. Much better than 6-700+
As I was saying,
‘Award-winning photograph’ is better than any number of ‘photorealistic’s, but just in case, I named a specific, high-end camera. That will almost always get you a great result, as long as you use the right camera. I mentioned the camera at the start of the prompt, because, well, having a high-quality photograph seemed important to my man Face Face. ‘Dynamic composition’ forces the AI to think of ways to make the shot interesting. ‘Dynamic poses’ forces your character to do something interesting as well. Putting the ‘dramatic lighting’ up top accomplishes the same thing: the AI is now on its toes and knows that whatever they are making, it has to look cool. I went with the more interesting lighting choice and added a light behind her and below her. An uplight improves faces tremendously, and a rim light makes the character stand out. And just looks cool.
‘European’ is the best way to ask for a white woman, and saying it twice is probably enough. If you are still getting Asians, make her face European and pale (keep it to one face, though – ‘pale European face,” not “European face, pale face. Stable Diffusion is known to add an unwanted extra face here and there.)
The ‘piercing’ eyes
will make her look into the camera (and possibly turn them blue – even more European!).
Noting her shoes and hair is a more effective way to get a full-body shot than asking for a specific camera angle. I also asked for a wider camera shot by mentioning the setting at the beginning of the prompt. The closer to the start the scene goes, the wider the camera angle will be.
A quick warning about wide shots: full body shots are where the majority of my deformed characters come from, and their eyes always look like crap. Try asking for a ‘cowboy shot’ instead, which is essentially head to knees – just barely close enough that the character’s eyes might not look horrendous.
Wombot Tip: If you are using Wombot on an 18+ server and can’t put any words with ‘boy’ or ‘girl’ in them into a prompt, ‘American shot’ does the same thing. French filmmakers thought the cowboy shot, which was designed to show off the cowboys’ guns as they faced off, ready to Draw! when the noon bell rang, was an absurd and quintessentially American camera angle, so they called it an ‘American shot’ derisively. Say ‘American shot’ in your snootiest French accent, and you’ll get it.
Lastly, I put the subject of the prompt last.
Most people say you should put them first, because they are the most important thing in the shot, but that is misguided. THEY are not the most important thing in the shot; how they LOOK is.
I always mention how amazing my character’s eyes are as high up in the prompt as I can. Then their face. Those are the two body parts that AI models have the most trouble with, so let it start on them right away. Then any other body parts you want to call out. Then clothes and any other details about how they look.
Once you have all the important things out of the way, you can say who all those body parts belong to. The AI has already figured out it was a woman from the ‘beautiful’s, so if you are not asking for a particular kind of woman, you can honestly not even mention her and save a token on ‘woman.’ Most AI models default to ‘woman’ anyways.
The final two things I did:
- Describe the wand. Holding things like wands is sometimes tricky for AI-generated characters, but they can pull it off if the AI knows a few details about the object. In addition, things like magic wands mentioned at the end of the prompt often get ignored. Making it sparkly, silver, and magic lets the AI know that it is important, even though it is the penultimate detail in the prompt.
- The last detail: shouting “Action!” Your characters will look better, have wider camera angles, and most importantly, not be boring to look at if they have something to do. And walking toward the camera is another way to get her to look at the viewer. Now you just need some fairy dust, and you are all set. Let’s see what Wombot (my current stand-in for Stable Diffusion) will make with our new-and-improved prompt.
oh. ohhhhh. Now I get it. Crap.
Now I understand the 99 “face”s, and I feel a little bad for making fun of them. Not a lot bad, but a little. I totally ignored my own warning about wide angles because I wanted to get her slippers in the shot, and so I got these faces:



This poor, poor man must have kept trying and trying to get a full-body shot with a face that wasn’t completely melted, deformed, and/or rotting off her skull, and he finally cracked under the frustration. We’ve all been there, buddy. The eyes did it for me.

See, here’s the thing:
There are some things Stable Diffusion just can’t do. It was trained on 512×512 pixel pictures that had been optimized for the web. A face of a wide shot in a 512×512 pixel picture takes up maybe 50×50 pixels, if you are lucky. It’s usually also stripped of all but 255 colors, dithered, and full of JPEG artifacts. So we get crappy faces. I’m still not sure why they are so much crappier than everything else, but I think that each unique face is a new puzzle for the AI, whereas all silver lamé bras look similar. I also think that Stable Diffusion knows faces are very important, so it tries to make them look exactly like its pictures. which are, need I remind you, teeny tiny crap.
But don’t despair, Mr. Face my friend. Just because Stable Diffusion can’t generate a tiny face, doesn’t mean Stable Diffusion can’t make it look good another way. But if I start talking about inpainting, we’ll be here all. day. So let’s let someone else fix it for us.
This is GFPGAN.
Its entire purpose in life is to upscale pictures of people and fix their faces. I uploaded my best-looking picture that still had at least half a foot, and GFPGAN made fixed the eyes, unsquished the nose, and even made her little sparklies sparklier. Of course, this took 5 or six rounds of letting GFPGAN do its thing and using the result as a new input. Still easier than inpainting.
And now we have a beautiful silver-shoed European Fairy holding a magic wand. Stable Diffusion might have been a little liberal in its interpretation of a skirt and a blouse, but I’ll give it the benefit of the doubt on this one.
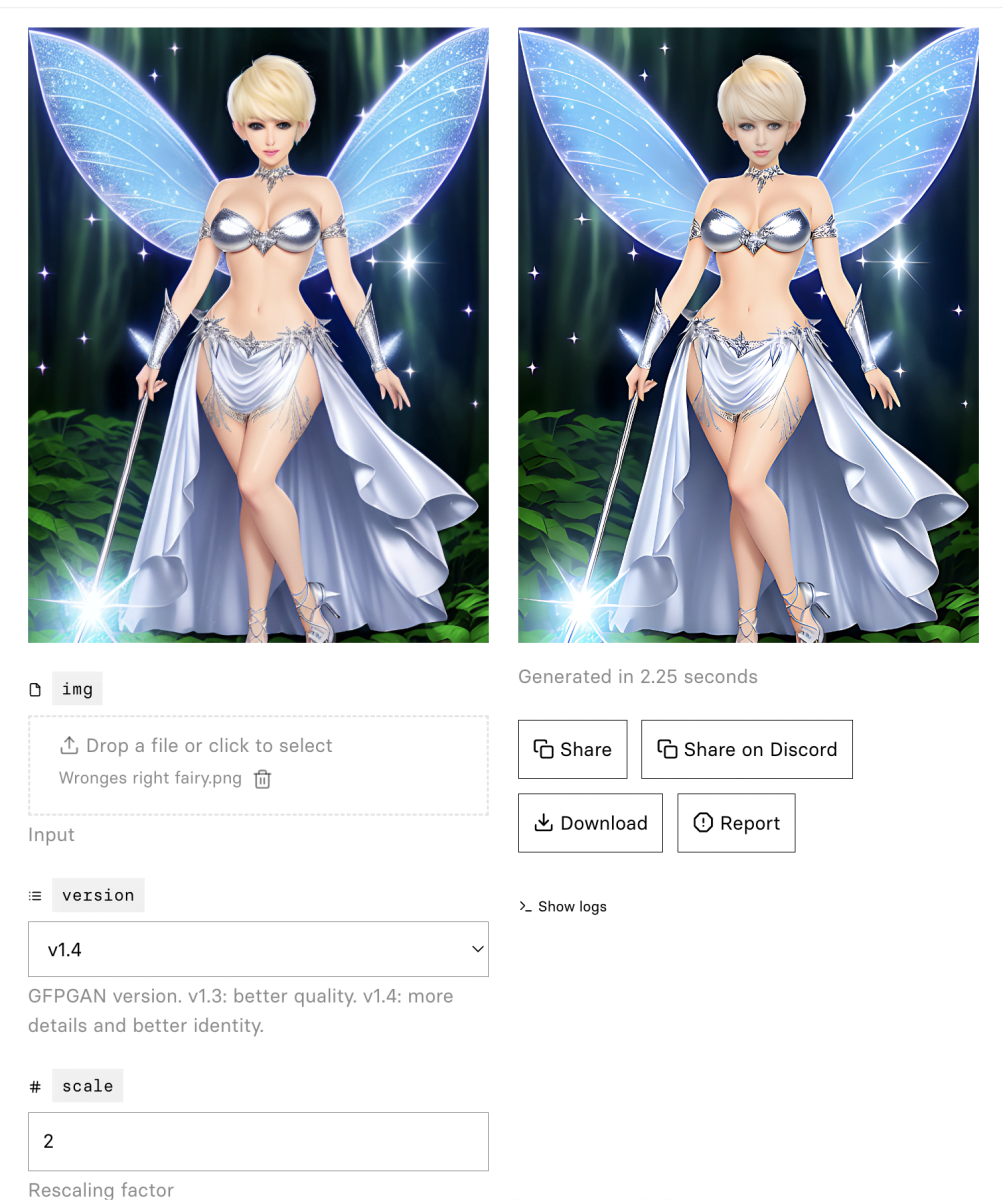

If you have any suggestions
of other ways to fix faces – or anything else that might prevent a tragedy like this from happening again – let me know in the comments. Or send me an email at alzakex@toplessvelociraptor.com. Or do both – the repetition would be very appropriate. Also, if you have any clue why he uses ‘perforation’ or what ‘edas waves’ are, I am dying to know, but have so far only been confused by my research. ‘Edas’ could be a cool-ass purse, could refer to a company that does conference registration, or could be eDas ™, the eDocument Authentication Service. As far as I know, none of those have waves. If you have any clue about this, leave a comment.
Oh, snap! I totally almost forgot to get to the thing I said I’d get to. Here it is:
Photographs are NOT “photorealistic“
For the love of all the Elder Gods, please, I beg you: stop using ‘photorealistic’ in prompts for photographs.
Nobody but you fools has ever called a photograph “photorealistic.” The people who wrote the texts for the text-image pairs that AI models were trained on sure as hell didn’t.
“Photorealistic.” is only ever used to describe things that **ARE NOT PHOTOGRAPHS,** like CGI.
If you are confused as to why your prompted photos always come out looking a little off, a wee bit plasticky, just on the other side of the uncanny valley, so to speak, it is because you are using “photorealistic.” wrong. If you are under the false impression that it is improving your prompts with realistic people and scenes, I assure you, it is not. Just stick with some variation of “highly detailed” and/or “beautiful/perfect” and we’ll all feel a little better. You’ll get pretty images, and I won’t have to see (as many) dumbass prompts.
/rant
Leave a Reply
You must be logged in to post a comment.